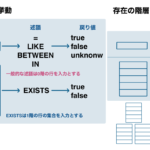
数ヶ月前に『達人に学ぶSQL徹底指南書 第2版 初級者で終わりたくないあなたへ』を読みました。
SQLの集合指向を理解するためにHAVING句の理解は必須だと思います。
特に、HAVING句では、COUNT(*), MIN, MAXなどの集約関数を用いて集合の性質を調べるということをよく行います。この過程で集合の性質を調べるために、CASE式を使用してある列の値を0, 1に仕分けて、COUNT(*)でその個数を調べるという組み合わせ方法も理解しておきたいところです。
(Oracle Live SQL で確認しています。)
HAVING句のサンプル
一般的には、WHERE句が「レコード」に対して条件を指定するのに対して、HAVING句は集合に対する条件を指定する句です。以下、使用例を確認していきましょう。
HAVING句のみで集約関数を使用してテーブルの状態を確認する
HAVING句は集合における条件なので、GROUP BY 句と同時に使用しなければいけないと思いがちですが、HAVING句のみで使用することが可能です。集合に対する条件、特に集約関数を使う場合には、WHERE句にCOUNT(*), MAX(列名)などの集約関数はかけないため、列における状態を確認する場合には、HAVING句に条件を記載することになります。
WITH TestScores (student_id, subject, score) AS (
SELECT 1, '国語', 55 FROM dual UNION ALL
SELECT 1, '物理', 35 FROM dual UNION ALL
SELECT 1, '化学', 75 FROM dual
) SELECT 1 AS "すべてのスコアが50点以上"
FROM TestScores
HAVING MIN(score) >= 30
;生徒(student_id)毎に条件を確認したい場合には GROUP BY student_id を加えます。以下の記事に書いてます。

本書では集約関数を使用する例として、歯抜けの存在の有無をサンプルで紹介されています。連番であれば、行数と連番の最大値が等しくなるという性質を用いたサンプルですね。GROUP BY を記載しない場合は、GROUP BY () が省略されています。
-- レコードの欠損の有無を確認する
WITH SeqTbl (seq, name) AS (
SELECT 1, 'Alice' FROM dual UNION ALL
SELECT 2, 'Bob' FROM dual UNION ALL
SELECT 3, 'Charlie' FROM dual UNION ALL
SELECT 5, 'David' FROM dual UNION ALL
SELECT 6, 'Eve' FROM dual UNION ALL
SELECT 8, 'Frank' FROM dual
)
SELECT '欠損あり' FROM SeqTbl
-- GROUP BY ()
HAVING COUNT(*) = MAX(seq)
;このクエリを集合論の言葉で表現すると、自然数の集合とSeqTbl集合の間に一対一対応(全単射)が存在するかどうかをテストしている、ということになります。
達人に学ぶSQL徹底指南書 第2版 HAVING句の力
SQLではこのように集合の性質を別の集合だったり、別の性質と比較して条件として記述するということをよく行います。この方がシンプルに書けるからですね。
ある列にNULLが存在するかどうかも条件として、COUNT(*) = COUNT(列名) の判定_rは、COUNTに列名を指定することで、NULLを除外して数えるという性質を利用したりします。COUNT(*) = COUNT(列名) であれば、その列にはNULLが存在しないということになります。
最小値と最大値の間で欠損があるかどうかを確認するには、行数と(最大値-最小値+1)が等しいかどうかを確認します。
-- 最小値と最大値の間で欠損があるかどうかを確認する
WITH SeqTbl (seq, name) AS (
-- SELECT 1, 'Alice' FROM dual UNION ALL
SELECT 2, 'Bob' FROM dual UNION ALL
SELECT 3, 'Charlie' FROM dual UNION ALL
SELECT 4, 'David' FROM dual
)
SELECT
CASE WHEN COUNT(*) <> MAX(seq) - MIN(seq) + 1 THEN '欠損あり'
ELSE '欠損なし'
END AS "欠損の有無"
FROM SeqTbl
;| 欠損の有無 |
|---|
| 欠損の有無 |
最頻値を求める
本書に記載なのは、以下の方法による標準SQLです。
- ALL述語の利用
- 極致関数の利用
が、ここではOracleの独自関数を用いて、最頻値を求めてみたいと思います。
以下のテーブルで考えてみます。
WITH TestScores (student_id, subject, score) AS (
SELECT 1, '国語', 55 FROM dual UNION ALL
SELECT 1, '化学', 75 FROM dual UNION ALL
SELECT 2, '英語', 70 FROM dual UNION ALL
SELECT 2, '数学', 65 FROM dual UNION ALL
SELECT 3, '英語', 75 FROM dual UNION ALL
SELECT 3, '数学', 70 FROM dual UNION ALL
SELECT 4, '国語', 70 FROM dual UNION ALL
SELECT 4, '英語', 75 FROM dual
)最頻値が1つに絞られる場合は、STATS_MODEを使用します。
複数の最頻値が存在する場合、Oracle Databaseは1つの最頻値を選択し、その値のみを戻します。
-- STATS_MODE
SELECT STATS_MODE(score) AS mode_rating
FROM TestScores;
;複数の最頻値を返す場合は、以下のようにscoreと各scoreの個数の組み合わせの集合と、その最大値とでサブクエリから求める方法がOracleのリファレンスで紹介されています。
SELECT score, cnt1
-- scoreと各scoreの個数の組み合わせの集合
FROM (
SELECT score, COUNT(score) AS cnt1
FROM TestScores
GROUP BY score
) t
WHERE cnt1 = (
-- scoreの個数の最大値
SELECT MAX(cnt2)
FROM (
SELECT COUNT(score) AS cnt2
FROM TestScores
GROUP BY score
)
);本書でもその2で紹介されていますが、scoreと各scoreの個数の組み合わせの集合からWHEREで個数の条件を適用する部分は、HAVING句で置き換え可能です。
SELECT score, COUNT(*)
FROM TestScores
GROUP BY score
HAVING COUNT(*) = (
SELECT MAX(cnt2)
FROM (
SELECT COUNT(score) AS cnt2
FROM TestScores
GROUP BY score
)
);このことから、[FROM句+GROUP BYで集合の階層を上げる + WHERE句の条件] = HAVING句 ができそうです。つまり、FROM句+GROUP BYで集合の階層を上げることで、WHERE句の条件にも適用できるということでもあります。
GROUP BY を使用する、使用されているSQLを見るときは元のテーブルから階層が1段階上がっているという認識があると集合の観点から理解しやすそうですね。
HAVING句の応用
以下、HAVING句による他のSQLの機能の組み合わせを確認していきます。
HAVING句とCASE式
冒頭でも述べた通り、HAVING句とCASE式の相性は良いです。というのは、HAVING句が集合に対する条件を指定するのに対し、本書でも述べられている通り、CASE式が要素(=行)が特定の条件を満たす場合に集合に含まれるかどうかを決める関数(特性関数)であるからです。
つまり、CASE式で各レコードの要素を振り分けて行った結果(集合)に対して、HAVING句で条件を指定するという使い方ができます。
WITH TestScores (student_id, subject, score) AS (
SELECT 1, '国語', 55 FROM dual UNION ALL
SELECT 1, '化学', 75 FROM dual UNION ALL
SELECT 2, '英語', 70 FROM dual UNION ALL
SELECT 2, '数学', 65 FROM dual UNION ALL
SELECT 3, '英語', 75 FROM dual UNION ALL
SELECT 3, '数学', 70 FROM dual UNION ALL
SELECT 4, '国語', 70 FROM dual UNION ALL
SELECT 4, '英語', 75 FROM dual
)以下は、国語のテストのデータがある場合に生徒と国語の点数を表示するサンプルです。
-- 国語のテストのデータがある場合、生徒と国語の点数を表示する
SELECT
student_id
,SUM(CASE WHEN subject = '国語' THEN score ELSE 0 END) AS 国語の点数
FROM TestScores
GROUP BY student_id
HAVING SUM(CASE subject WHEN '国語' THEN 1 ELSE 0 END) > 0
;生後毎にグループで切り分けて、その中で国語のテストを持つ場合は1として加算、点数の方は同様にCASE式で国語であれば点数として加算することでラベリングを行っています。CASE式に関しては以下に記事で紹介しています。

HAVING句と全称量化
テーブルは先ほどのTestScoresを利用します。ここでは、各生徒が受けたテストが2つまでと仮定すると、「すべてテストが英語と数学の生徒」という全称量化の命題を解くこととします。
全称量化は、集合全体の行数と(ここでいう生徒の科目の行数)と状態の行数(英語と数学を合わせた行数)が等しいことによる性質を利用するので、HAVING句と相性が良いです。
SELECT
student_id
FROM TestScores
GROUP BY student_id
HAVING COUNT (*) = SUM(CASE WHEN subject IN ('英語' , '数学') THEN 1 ELSE 0 END)
;